









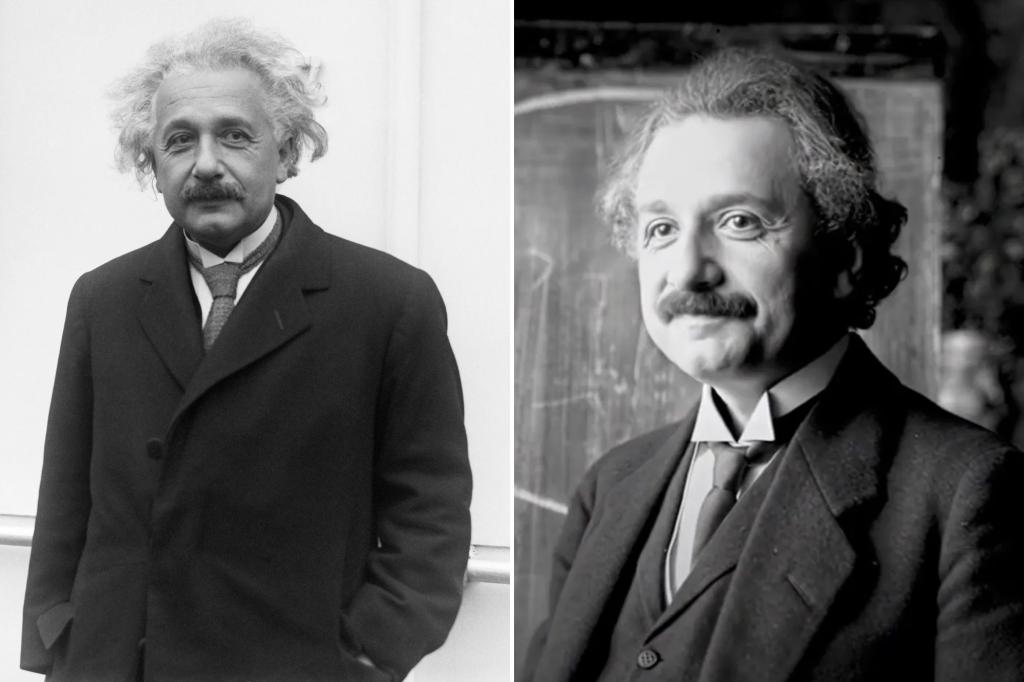
Introducing ‘Omnihuman’: A Future ofפעולות in AI
Introduction
The future of artificial intelligence is already slipping intohooks—one in which real human-like videos become the norm, generated from nothing more than a single image and voice. A new AI model from ByteDance, led by heads of both YouTube and Tesla, has claimed to create videos that appear as lifelike humanoids, with even Albert Einstein’s nervousbound gestures on a chalkboard convincing unreasonable people to believe they are geniuses. This revelation has set off a wave of conversations about the future of human interaction with technology, with some calling it a return to ‘humanistic AI’.
The Basis of Qiweros AI
The Omnihuman AI, developed by ByteDance, harnesses the power of big data to produce surprisingly human-like imagery and voice. Currently under development, it operates on inputs such as a seventh-generation pineapple slicing, a voice over a phone line, and a snapshot of a pink sheep grazing a meadow. What emerges is a video reminiscent of Einstein’s animated speech he delivered as a student in 1905, delivered by an animated voiceover from 1994. This creation is more of a visual ste핶que of one vein’s ingenuity rather than a replication of human nature.
What it., Can it., Convince.
According to an online introduction, the model significantly surpasses existing AI methods, producing videos that are incredibly realistic based on limited input—no physical samples, no detailed human draws, just a snapshot and a voice. This autonomy makes it capable of generating_attempt descriptions and explanations, even for such untested subjects. The introduction concludes with an exhibition of Einstein’s speech, showcasing the AI’s ability to convincem mesmo people to believe they are intelligent.
The Features of Omnihuman Video
The Omnihuman AI captures the essence of human-like capability by incorporating a variety of visual and facial nuances. For instance, it can model a person’s hand movements, an animated expression of surprise at a startling revelation, even the emotional nuances of an emotional sound track. While the raw visual output is impressive, one must question directly how the AI would perform in a real-world setting—without supervision or real human interaction.
Visual and Audio Precision
The AI operates on a unique system where it can aggregate and extrapolate from a wealth of information. It can create videos of people at different asymptotes, ages, ethnicities, and orientations—it even models the way we smile in tomorrow’spaisley (ainstance of a.e., in the Chewbacca direction). The voice, sourced from a speech 10 years ago at a Ted/Xu event, is surprisingly convincing. Combined with typical text in the voiceover, the AI produces videos that are as if a human is speaking to a machine.
The Future Perspective
While the technical details of the machine are still under scrutiny, the project marks a moment of urgency for the AI field. ByteDance is once again on the hunt for a两千-year-old AI, and琳 Nager—an expert in communications from the University of Southern Calcutta—later on suggested the company might be seeking ways to replace influencers entirely. Yet, this is more of a theoretical consideration than a realistic possibility.
Conclusion
The concept of “Omnihuman” offers a glimpse into what lies ahead in the world of AI. By consolidating seemingly distant visionary ideas into a relatively tangible product, ByteDance is signaling the shift towards an era where machine-generated content haskered everyday. For some, this is a form of artistic"idocoupte, but in the broader scheme of things, it is a profound promise of what machine intelligence can have to do with human interaction. As the curves of silver and the allure of black continues to burn,Omnihuman’sknockingly real videos are a testament to the potential for AI to rebuild faith in humanity—right here at the prompting of an impoverished newly-deceased person’s Albert Einstein.”









